Speech recognition with Python in 12 lines of code - Play the radio!
Contents
Did you ever want to create your own Alexa, Siri & co.? Python’s fantastic speech recognition package enables you to quickly create your own custom commands. And the best part: you can decide what kind of speech recognition you want - online or offline! So let’s get started!
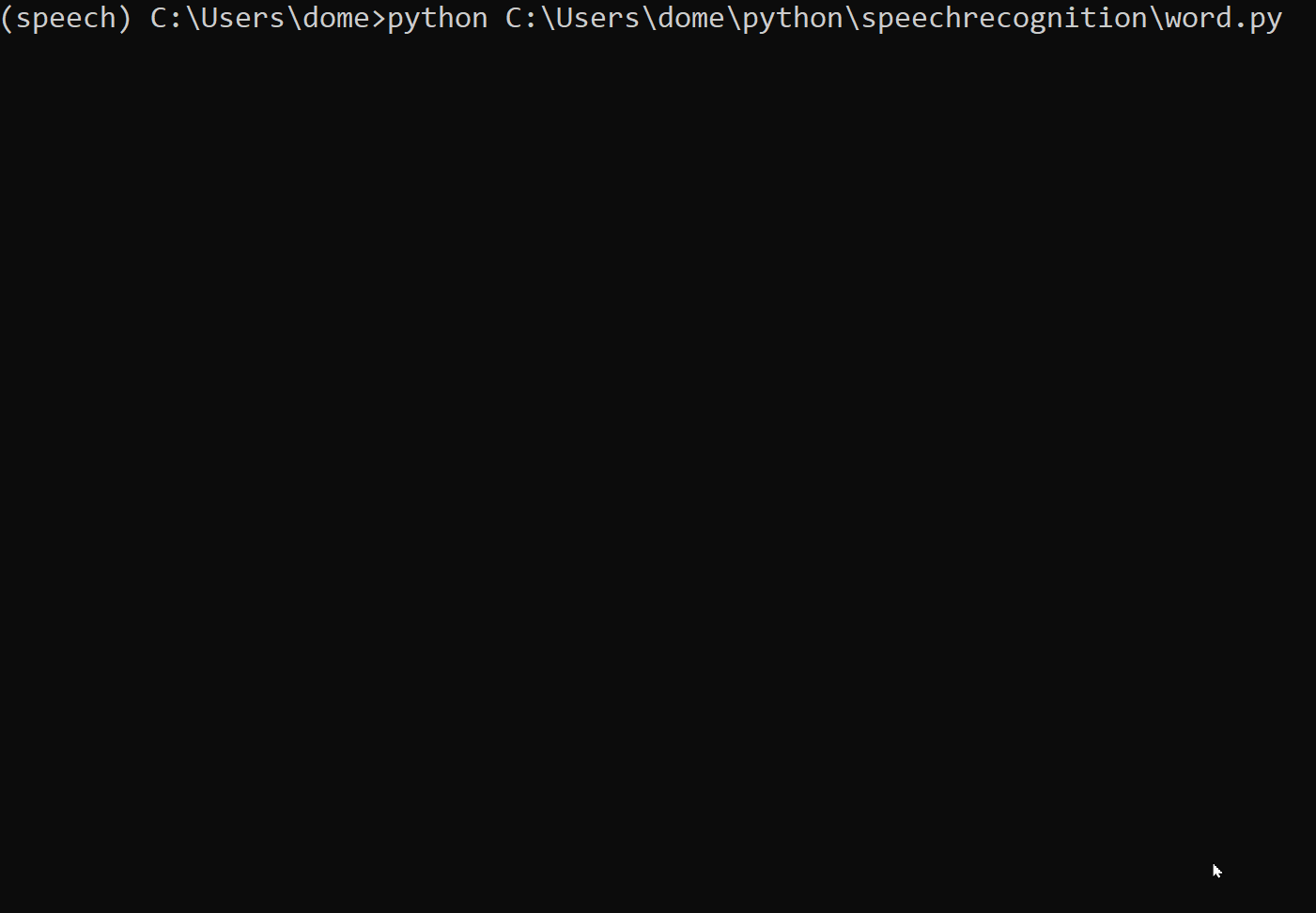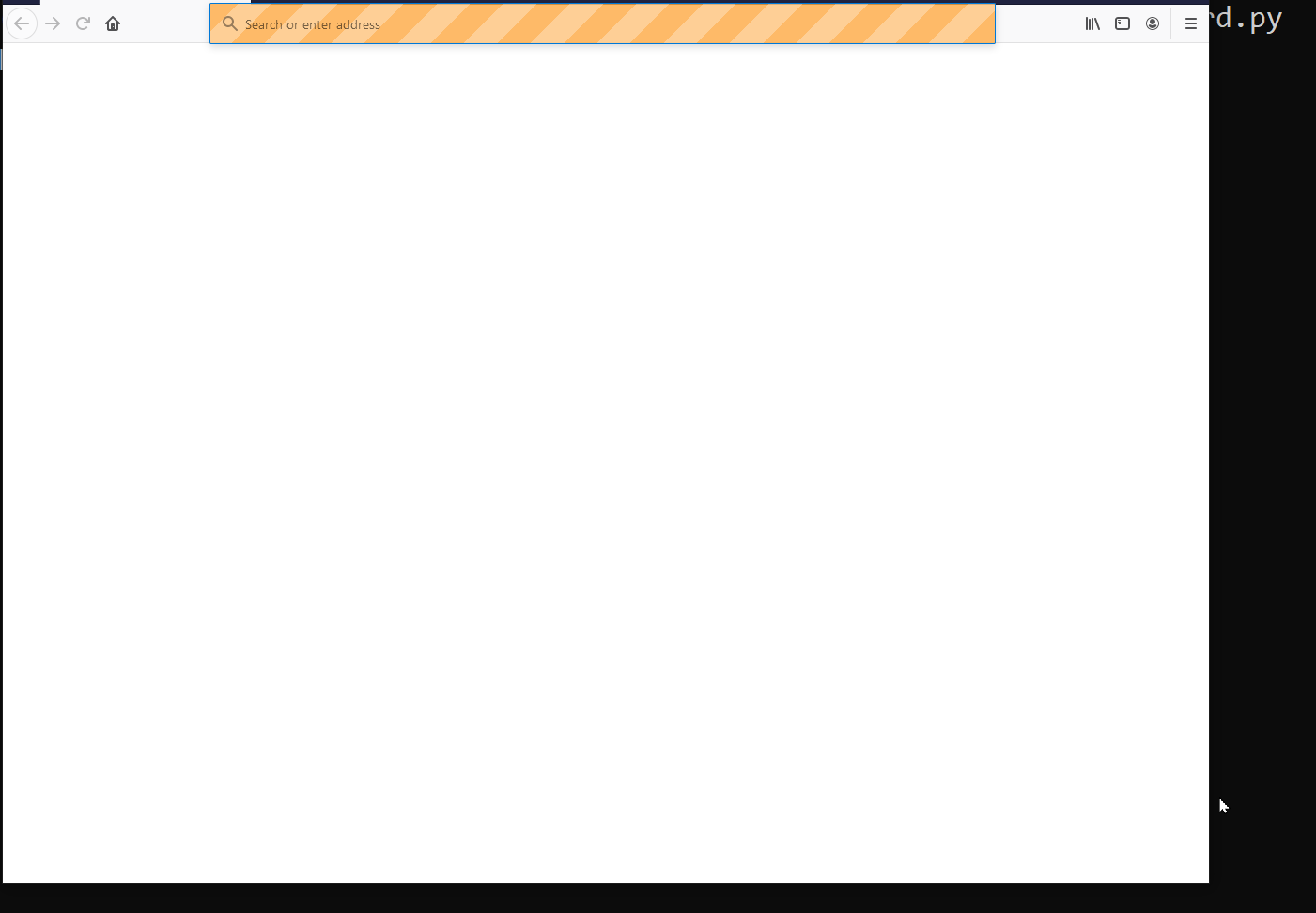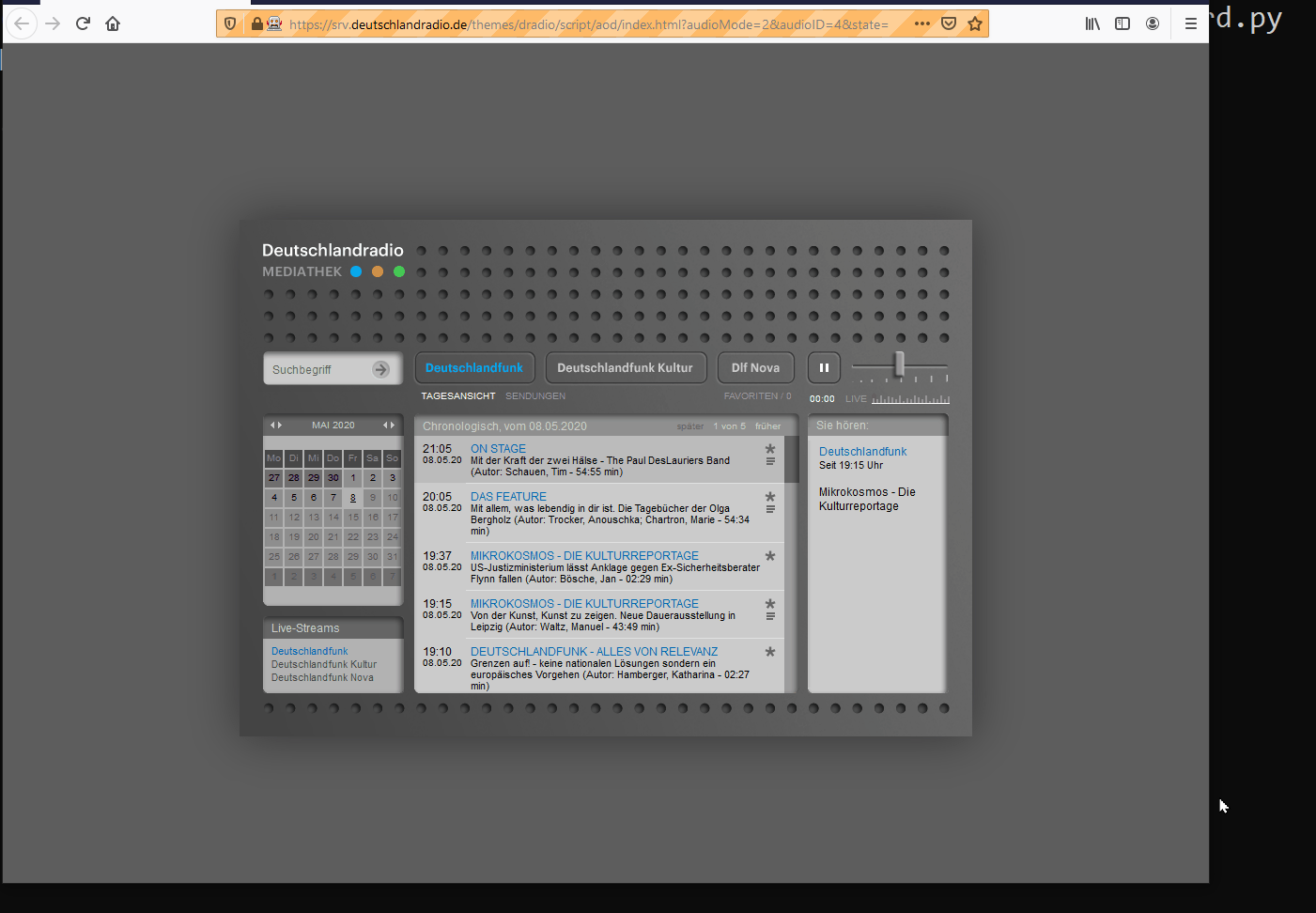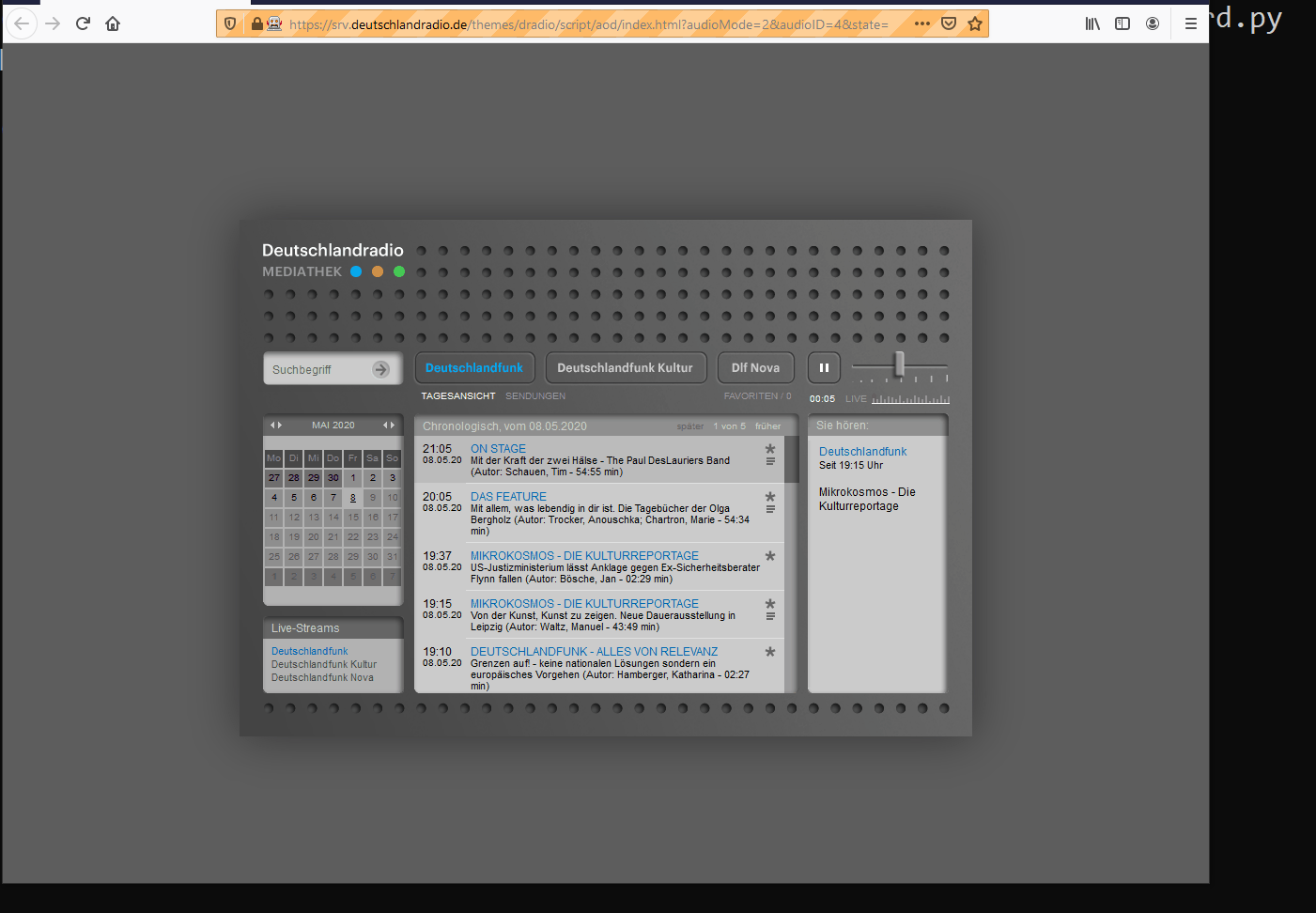
Also see the github repo associated to this article.
The aim
We want to write a script that does two things for us.
- Recognize whether we say the keyphrase “play the radio” or not.
- If so, open a browser tab, navigate to an online radio page and click the play button.
The following steps require some familiarity with Python, Anaconda (or miniconda) and virtual environments. If you don’t know about Python yet, great! You can start right now with Socratica’s Netflix-like, well structured, incredibly entertaining and captivating Python tutorial. If you’re into Python already, I can definitely recommend to watch it anyway.🦉
Setting up a virtual environment
Create a virtual environment named “speech” with conda and install the neccessary packages. Execute these commands one after another and check on errors.
| |
If you get lost with conda commands take a look at the cheat sheet.
Download browser drivers for selenium
For Chrome download Google’s Webdriver, for Firefox get Geckodriver. Put this file in an accessible folder.
Write and customize the script
Let’s take the script and go through it.
| |
Done! The script works now and can easily be customized. If we would like to chose between two different phrases, let’s write a function for the button clicking. This time we’ll use Firefox.
| |
Chose your engine
In this example I’m using Google’s speech recognition for convenience. Google’s engine is handling all the hard part of recognizing your voice and formatting it to nice text. Since it works as an API, it requires you to be online. However, the speech recognition package also features offline recognition powered by Snowboy or CMUSphinx. In order to make it work it requires a little more effort, but it enables you to do a lot more.
Have fun experimenting! 🐳
Credits
- Gif by me

 This article is licensed under CC BY 4.0
This article is licensed under CC BY 4.0