DuckDB for Geospatial
Contents
Using DuckDB for geospatial workflows for incredible performance boost! Leveling up my GeoPandas workflows for processing the 100M Foursquare dataset.
Image Source: Foursquare
This blog article, as my previous ones, have been written by myself. No GenAI was used except for improving code and doing research.
Motivation
The past two years were fantastic years for open data. Just to name a few fundamental releases:
Overturemaps: first non-beta dataset in 2024, now grown to more than >50.000.000 places https://overturemaps.org/
Foursquare: released >100.000.000 places in November 2024 https://docs.foursquare.com/data-products/docs/places-data-overview
EU High-Value Datasets Regulation (2023/138): in force since June 2024, finally forcing EU member states to open all kinds of datasets like parcel data, DOPs, DEMs/DSMs etc. Read through the annex what kind of spatial datasets to expect https://eur-lex.europa.eu/eli/reg_impl/2023/138/oj
EU 2023/138 Annex
Datasets | Administrative units | Geographical names | Addresses | Buildings | Cadastral parcels | Reference parcels | Agricultural parcels |
Granularity | All levels of generalisation available with a granularity up to the scale of 1:5 000 . From municipalities to countries; maritime units. | N/A | N/A | All levels of generalisation available with a granularity up to the scale of 1:5 000 . | All levels of generalisation available with a granularity up to the scale of 1:5 000 . | A level of accuracy that is at least equivalent to that of cartography at a scale of 1:10 000 and, as from 2016, at a scale of 1:5 000 , as referred to in Article 70(1) of Regulation (EU) 1306/2013. | A level of accuracy that is at least equivalent to that of cartography at a scale of 1:10 000 and, as from 2016, at a scale of 1:5 000 , as referred to in Article 70(1) of Regulation (EU) 1306/2013. |
Geographical coverage | Single or multiple datasets that shall cover the entire Member State when combined. | ||||||
Key attributes | Unique identifier; Unit type (administrative or maritime unit); Geometry (6); Boundary status; National identification code; Identification code of the upper administrative level; Official name; Country code; Name in multiple languages (only for countries with more than one official language) including a language with Latin characters, when feasible. | Unique identifier; Geometry; Name in multiple languages (only for countries with more than one official language) including a language with Latin characters, when feasible; Type. | Unique identifier; Geometry; Address locator (e.g. house number); Thoroughfare (street); name; Administrative units (e.g. municipality, province, country; Postal descriptor (e.g. post code); Date of last update. | Unique identifier; Geometry (footprint of the building); Number of floors; Type of use. | Unique identifier; Geometry (boundary of cadastral parcels or basic property units (7)); Parcel or basic property unit code; A reference to the administrative unit of lowest administrative level to which this parcel or basic property unit belongs. | Unique identifier; Geometry (boundary and area); Land cover (8); organic (9); Stable landscape elements (10) (“EFA-layer”); areas with natural/specific constraints. | Unique identifier; Geometry (boundary and area of each agricultural parcel); Land uses (crops or crop groups); Organic; Individual landscape element; Permanent grassland. |
With all three however, the challenge is data harmonization. Peaking at the category systems of Overturemaps (>2000 entries) and Foursquare (>1000) the question remains how to bring OSM and those two together.
For researchers like me, all three are valuable data sources and fit my research on geospatial semantic search perfectly! Especially Foursquare as a social-media-like dataset where users could write anything to “check in” somewhere in any language and with sentiments is perfect for my use case. So let’s dive in!
Foursquare criticism
The quality of Foursquare data was discussed heavily online, as it includes lots of duplicates and weird artifacts that could have been easily fixed like POIs along the equator, around null island and so forth.
From an ethical and privacy perspective the dataset is certainly questionable as it includes hate speech and geoprivacy infringements.
Performance Comparison: GeoPandas vs. DuckDB Spatial
Basic Example: Loading and String Filtering
I recently processed the entirety of more than 100.000.000 Foursquare places and created an httpfs-based data exploration workflow. That means that I provide a data dump on Huggingface (https://huggingface.co/datasets/do-me/foursquare_places_100M) as parquet file that you can explore and filter wihtout having to download everything. Instead, you can use DuckDB on your device and query the data remotely. The parquet file structure is quite advanced, so your DuckDB client will (almost) only pull the data needed.
For example, filtering the full 10Gb file remotely for all entries containing the word bakery, takes only 70 seconds on my setup. I’m using Python 3.11 here with duckdb installed.
| |
For convenience and better formatting I added a .df() at the end so the results get converted to a pandas df right away.
If instead you download the full file and query locally, the exact same query only takes 4.5 seconds!
| |
For comparison, only for loading this file, geopandas takes 2-3 minutes (!):
| |
Filtering in geopandas then is fairly fast but expectedly much slower than DuckDB with 19 seconds:
| |
Spatial Filters
Now, let’s use a spatial filter! Let’s say we’d like to export a file with only the locations in Germany. In GeoPandas, it’s straightforward, but the problem is that we first need to load the file and waste precious time again. Instead, let’s use DuckDB here. For simplicity, let’s take a hand-clicked file I created with https://geojson.io/#map=5.29/51.102/10.383.
| |
Now save this as germany.geojson in the working directory and run this code. The output is the filtered pandas df.
| |
This code executes in only 22.3 seconds on my M3 Max! I was completely blown away. Remember that only for reading the file, geopandas takes 2-3 mins, lol.
Now, if we use the remote file instead from my Huggingface dataset with:
| |
it will of course take much longer. I ran the test and it took 3:35m on my system - not bad! Certainly not worth downloading the whole file first. A great alternative if you need only subsets of really large files for local processing or lean web applications.
If you want to be very precise, you can use this OSMNX code to retrieve the exact OSM boundary of any country:
| |
However, in the case of Germany, it leads to a gigantic 4Mb (!) GeoJSON file that drastically drags down the processing speed. I would strongly advise against using the exact geometry and would rather simplify it. You can use this code:
| |
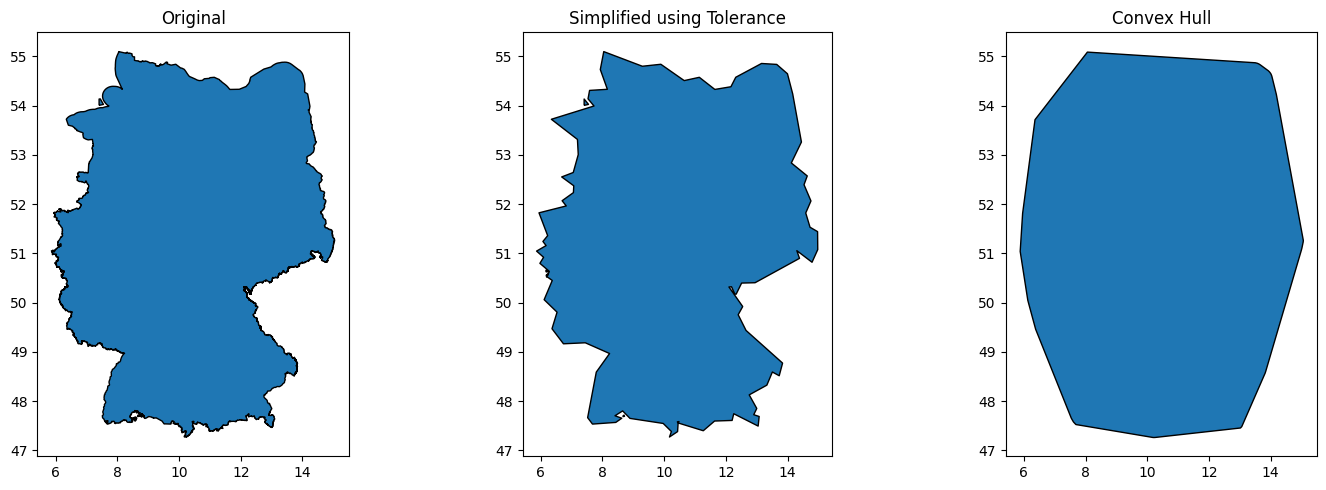
If you use the geometry that results from the file with a certain tolerance germany_simplified_tolerance.geojson, it takes only 45 seconds; using the convex hull only 33 seconds.
Httpfs/range requests compatible file formats
Now, there are different file formats that DuckDB can potentially read and that leverage httpfs/http range requests efficiently for very different purposes:
Flatgeobuf is one of my favorites as it’s optimized for spatial retrieval of simple features by bounding boxes. It’s incredibly fast and you can use it very efficiently in lean web apps.
Parquet is the swiss army knife of file formats and comes in handy everywhere. It does work for spatial purposes but is not as heavily optimized in this area as is Flatgeobuf. However, when it comes to column-based retrieval or complex filters, Parquet is likely to outshine Flatgeobuf.
Mbtiles & Pmtiles are both used for vector tiles and complex geospatial features. Protomaps is a beautiful example of what can be achieved with just a single file (currently 120Gb for the entire world basemap) and some advanced engineering. It replaces a full tile server with just a single static file. The client requests the exact file chunks needed for a particular zoom level and bounding box and renders it with a style of your choice in the blink of an eye.
COGs, so-called Cloud Optimized GeoTIFFs are the raster pendant to the above vector formats. They work similarly but focus on delivering efficient image delivery.
The are many more to add here, like of course SQLite with Spatiallite or Zarr.
Bonus: Geospatial Semantic Search
As you might guess, I am fascinated by these file formats. They replace heavy and costly server setups and are much more sustainable. And you can use them for (geospatial) semantic search too!
I understand Geospatial Semantic Search (GSS) as the user-driven process of employing semantic search to locate and rank similar documents to a user query on a map. Might sound easy but comes with a lot of tricky bananaskins that are not trivial to solve.
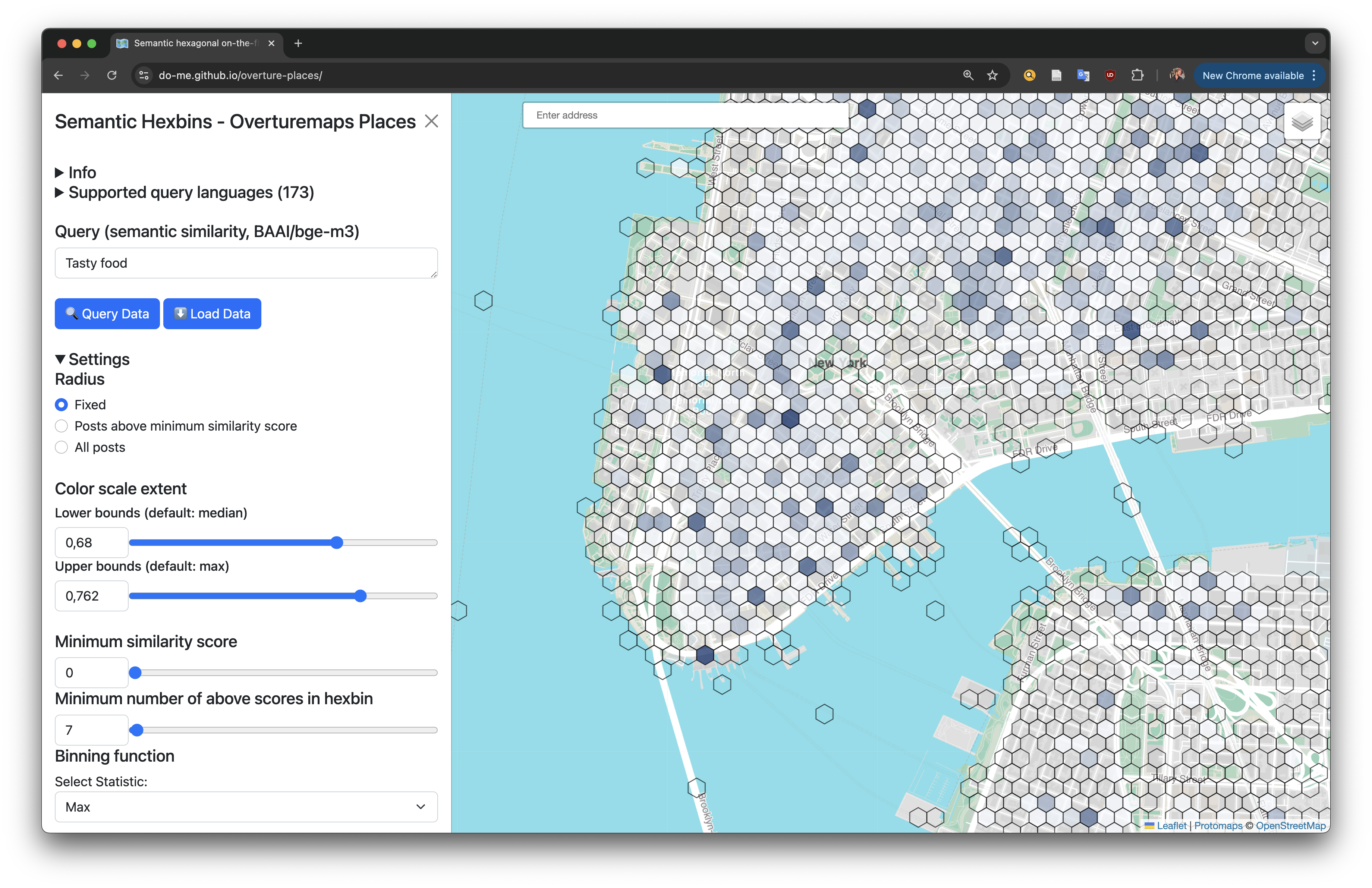
Based on Flatgeobuf, I created a single file for the Overture Places dump with bge-m3 embeddings for all the categories. In the frontend, a user can search anything in more than 100 languages (based on transformers.js) and gets a map with the most similar places. The entire app is hosted for free on Huggingface GitHub Pages. I will write a dedicated blog post about this workflow in the future.
You can try it yourself live here for your personal area of interest: https://do-me.github.io/overture-places/