English-only embedding models for multilingual docs
Contents
Text Embeddings: Speaking languages without learning them?
tl;dr: some *-en models perform well on other languages too.
Intro
While indexing plenty of XML files for semantic search, I noticed that some (not all) text embedding models designed for English only also perform fairly well on other languages!
Amongst those is e.g. FlagEmbedding (bge family) on of the best open source models for embeddings according to MTEB. For FlagEmbedding, a rule of thumb is: the larger, the better these models perform on other languages. It’s an effect caused by the distillation and pruning process of the large variants that were trained on data in multiple languages.
This is very handy as it makes your embeddings more resilient than you’d expect, if e.g. some French quotes appear in your text or your social media posts unexpectedly contain entries with other languages. Note that in these cases you should probably stick with good multilingual models anyway but if you can - statistically seen - neglect other languages *-en models would work just fine.
Test yourself
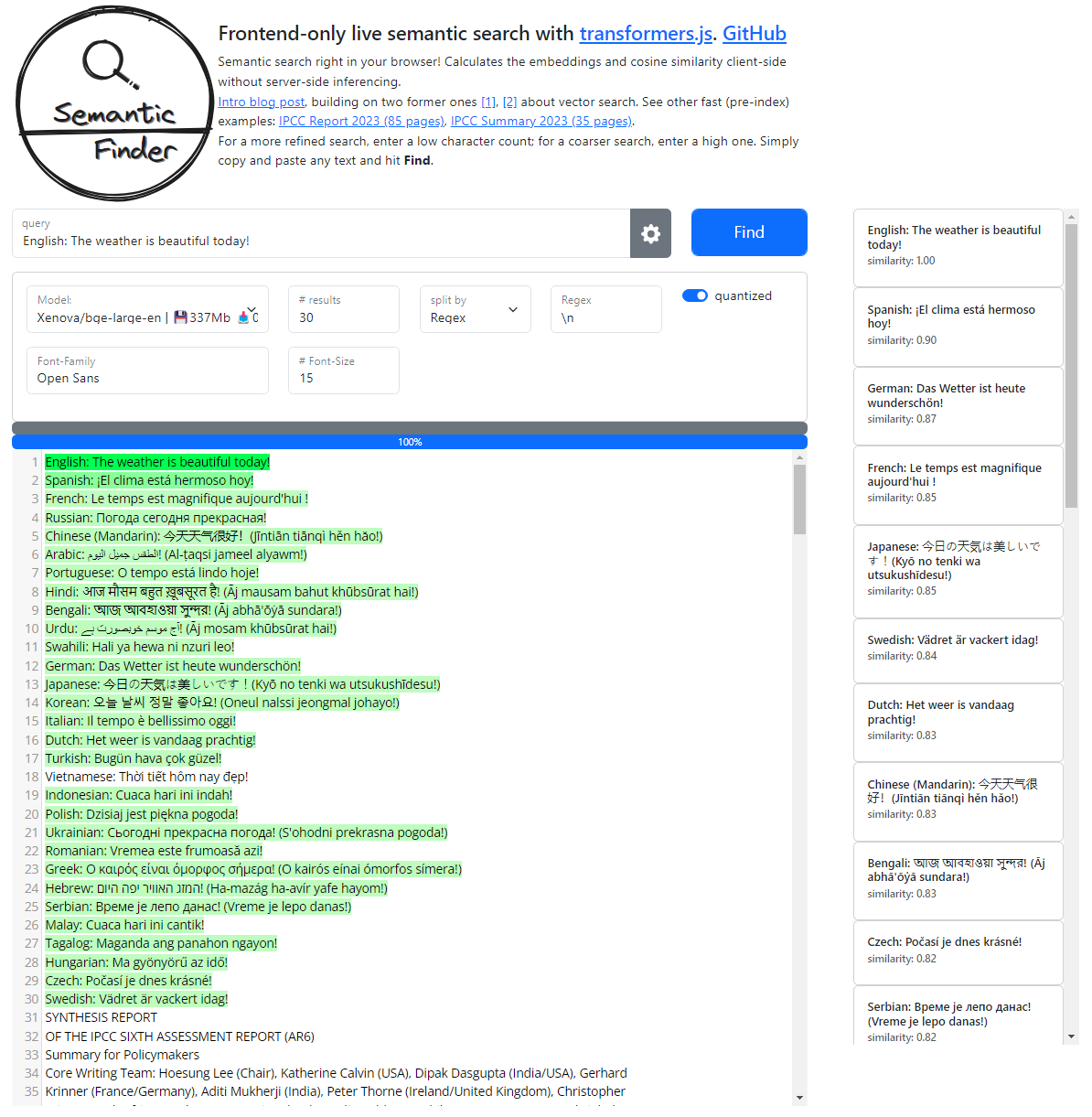
You can quickly test the behavior yourself with SemanticFinder. Steps:
- Add one sentence in 30 or more different languages. One row is one translation.
| |
Set the splitting option to regex and enter “\n” (separated by new line)
Add plenty of dummy data in other lines, e.g. here I added 1000 lines of the IPCC report dealing plenty with the topics climate and weather. You can find it here.
Run the test for different models and see how it changes.
The bge-large-en model performs well on 29 out of 30 languages!
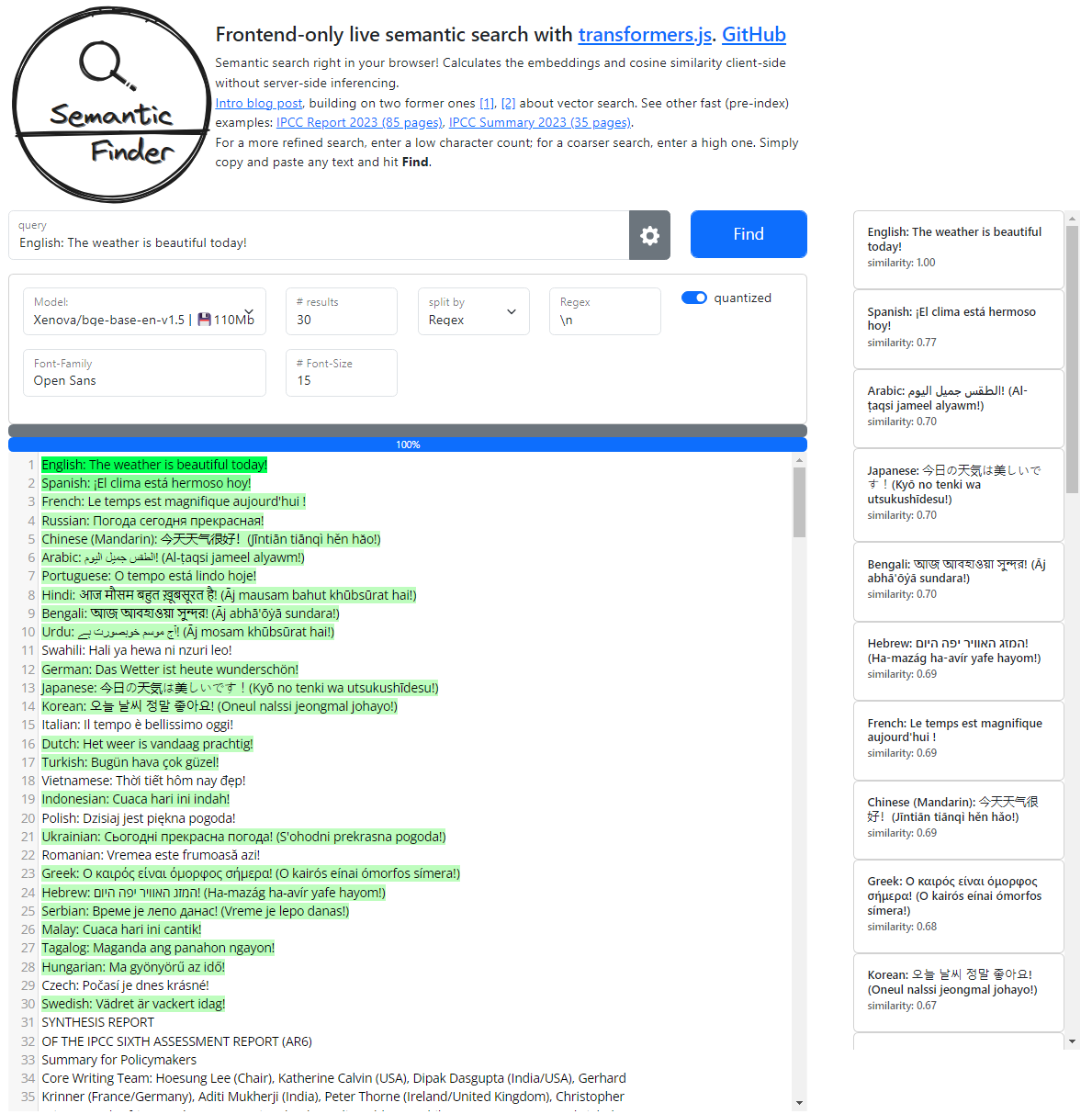
The bge-base-en model still performs well on 24 languages.
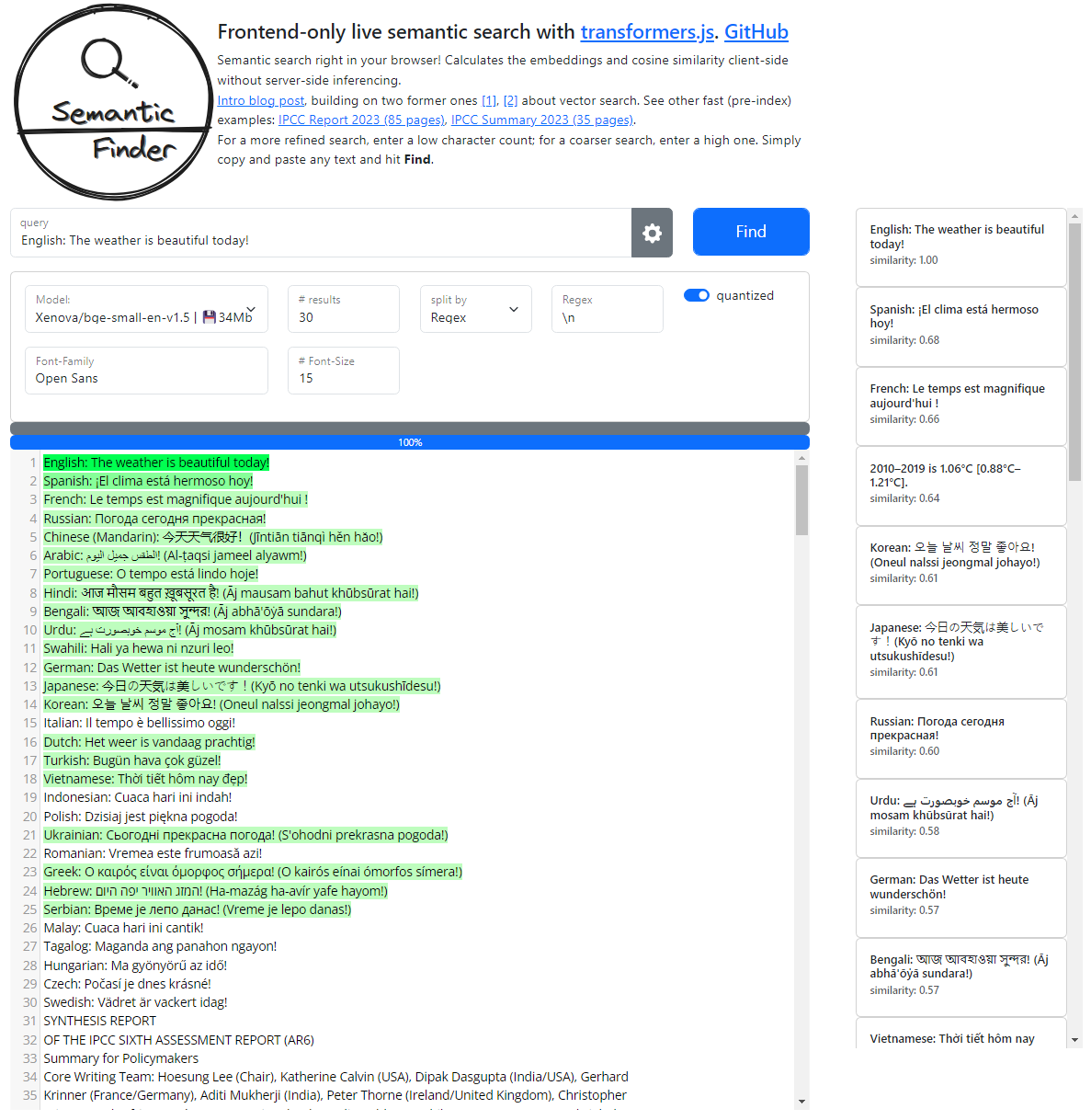
The bge-small-en model deals well with 21 languages instead. An expected degradation considering the model size.
Note that I used the quantized models here for faster performance. If you use the unquantized ones you can expect a boost in performance but a drop in quality.
Test any other model yourself with SemanticFinder running entirely in your browser!