Mining Instagram efficiently with Torpy - Fast Instagram Scraper
Contents
A fast and efficient Instagram Scraper based on Torpy. Scrapes posts for multiple hashtags and location ids.
Yet another DIY-scraper?
There are plenty of Instagram-Scrapers out there out of which Instagram-Scraper is still my favorite. However they didn’t entirely meet my needs so I went ahead and scripted two scrapers from scratch, each for different purposes. In an earlier post I explained how I wrote Simple Instagram Scraper which is a powerful scraper to get all post details, yet with the tradeoff of beeing relatively slow (5-10 seconds/post) due to blocking policies.
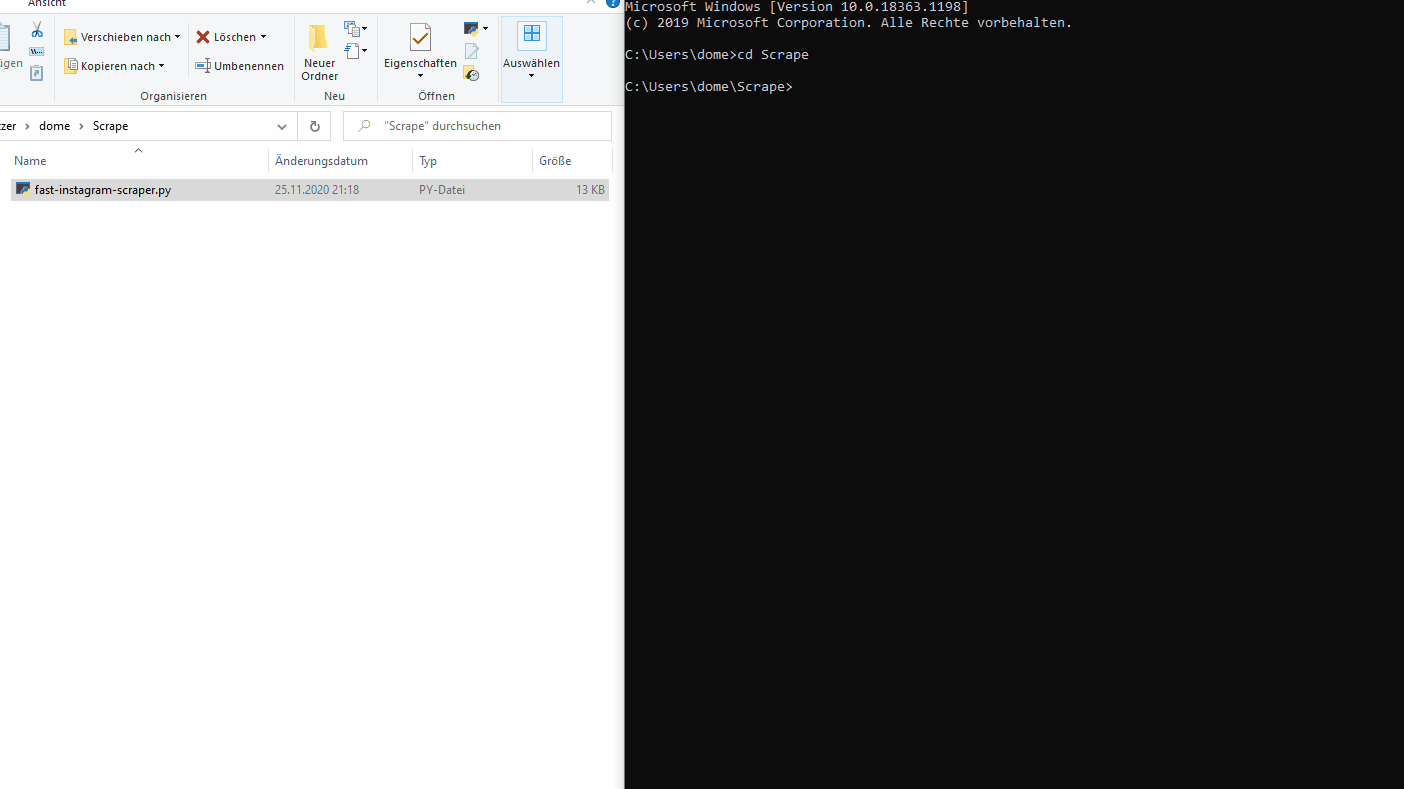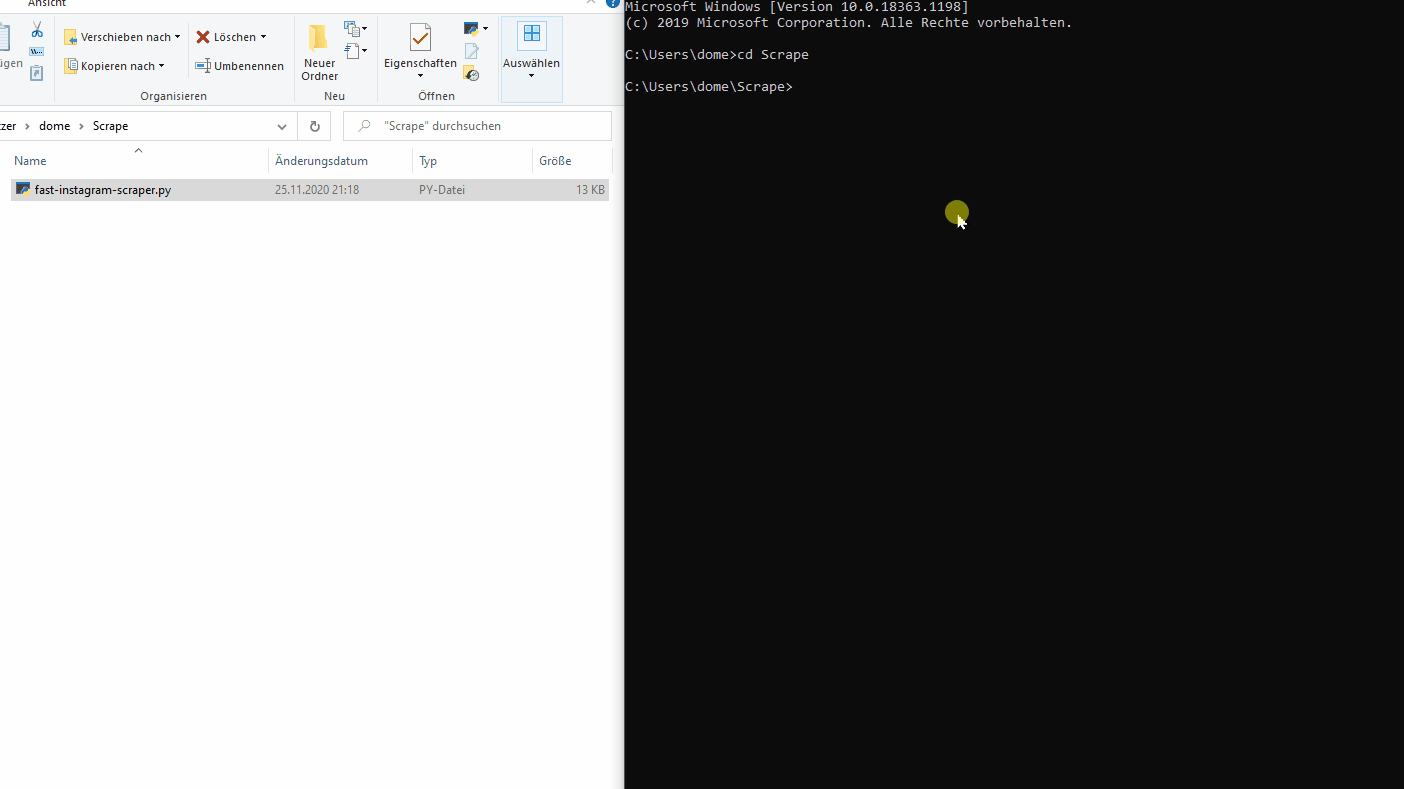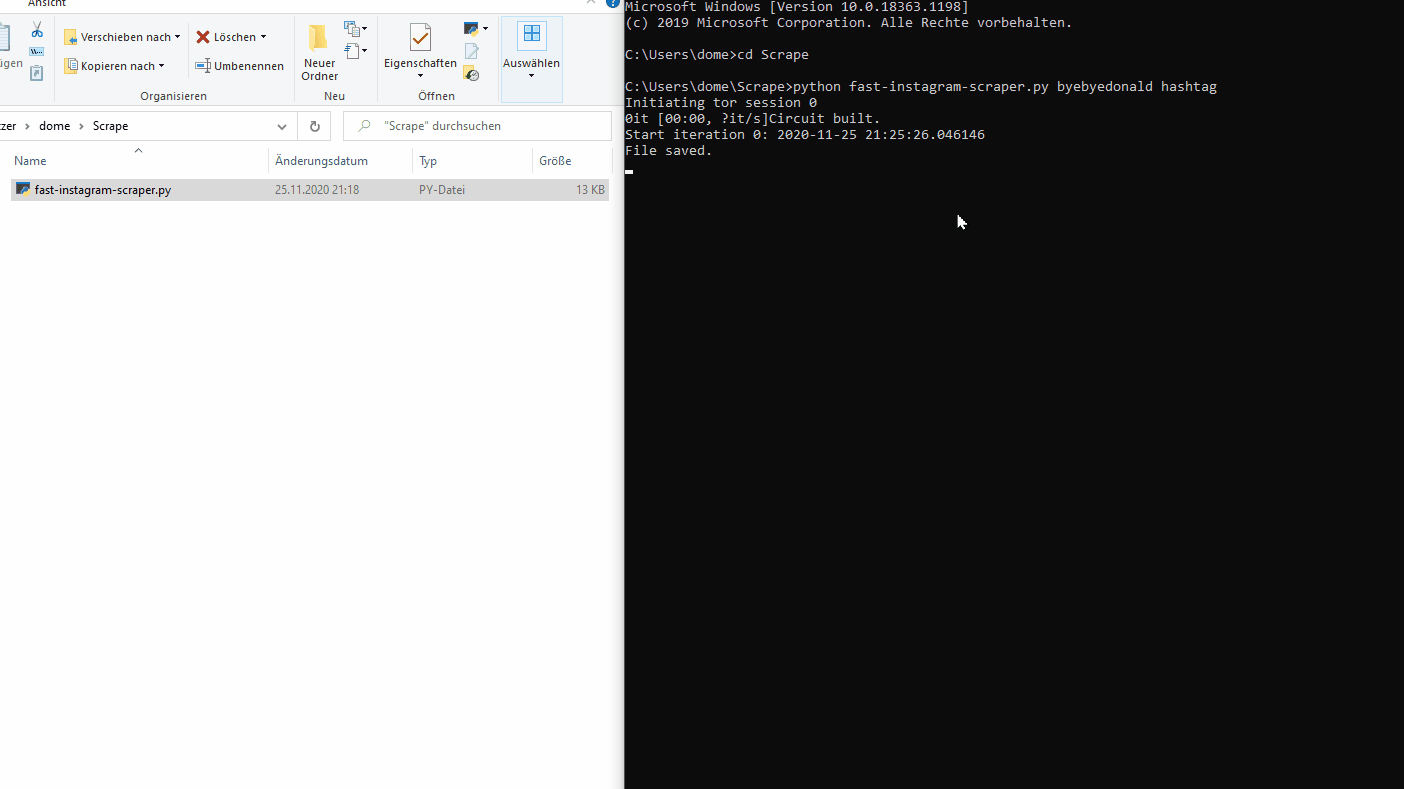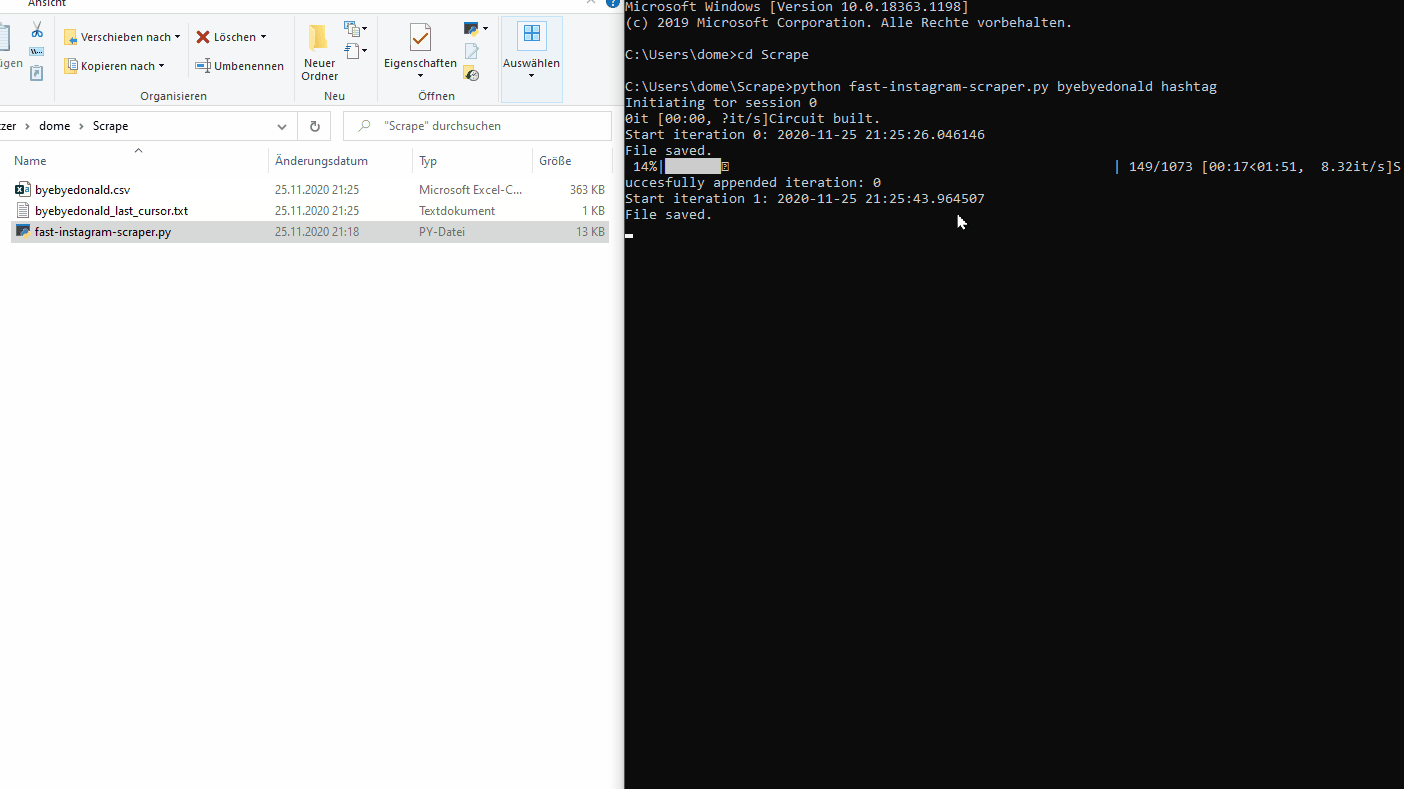
Fast Instagram Scraper was designed to be fast and efficient with the perk of using the TOR network powered by Torpy. When beeing blocked you simply change the end node and you are good to go. This technique allows to scrape way faster. Due a completely different approach of directly accessing Instagram’s JSON objects in batches of around 50 posts it achieves a rate of around 0.2 seconds/post or 5 posts/second. The major drawback is rooted in Instagram’s publicly available JSON objects: they don’t contain all post information. For example they lack important information such as location and accessibility captions (an automated image content description based on Facebook’s AI image recognition algorithm).
Scraper Comparison
| Scraper | Pro | Con |
|---|---|---|
| Simple Instagram Scraper | + all post information | - relatively slow - login required - max. 8-12k posts |
| Fast Instagram Scraper | + fast + no login required + theoretically no maximum | - not all post information |
Fast Instagram Scraper's Approach
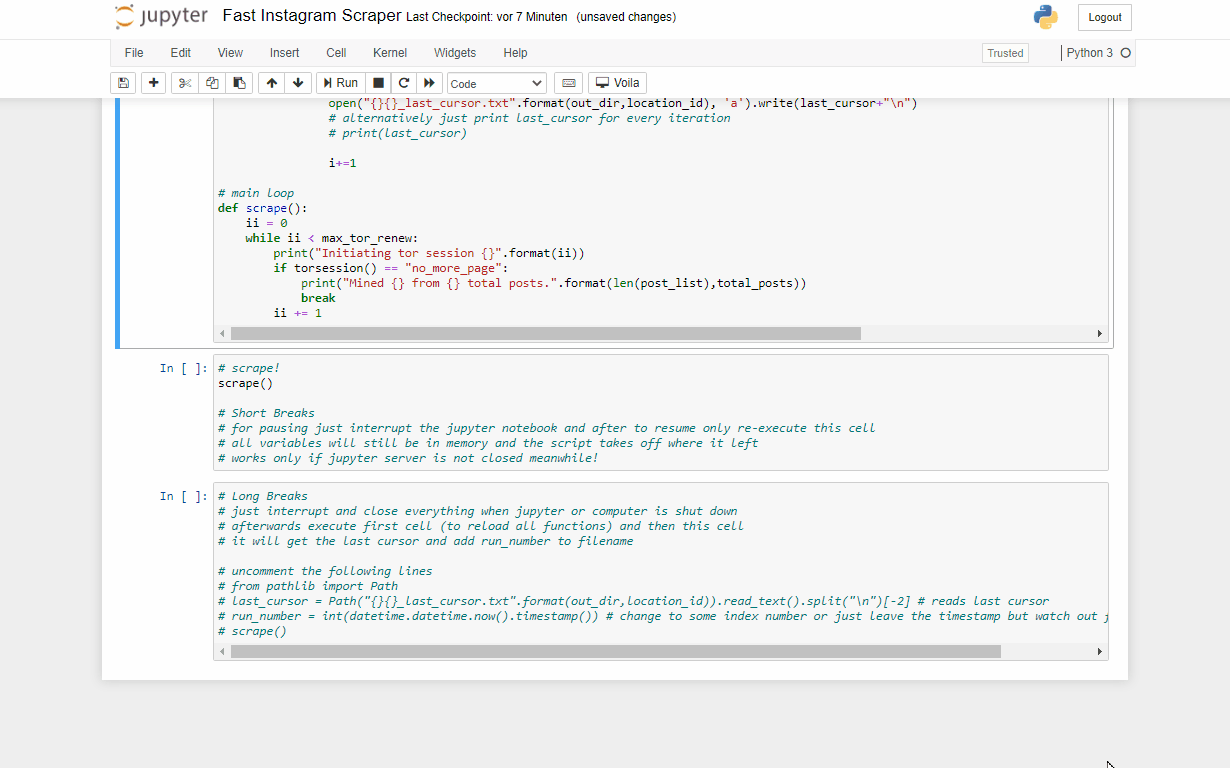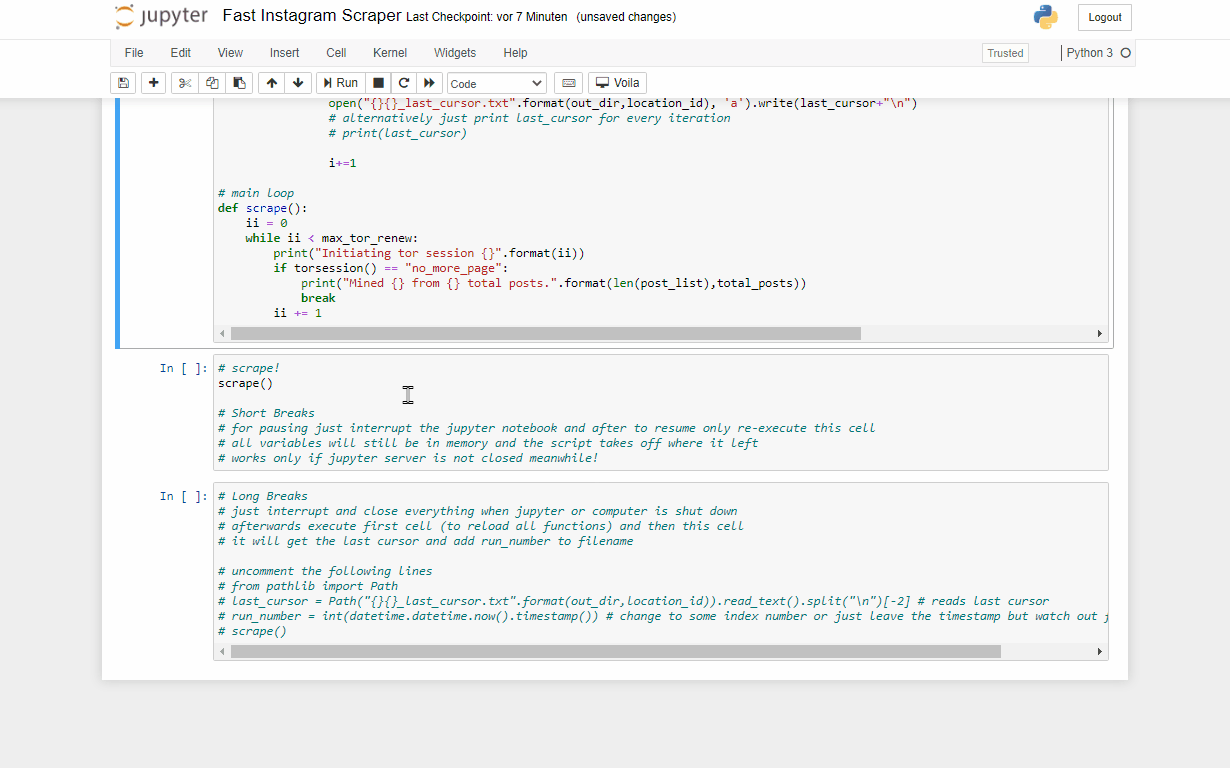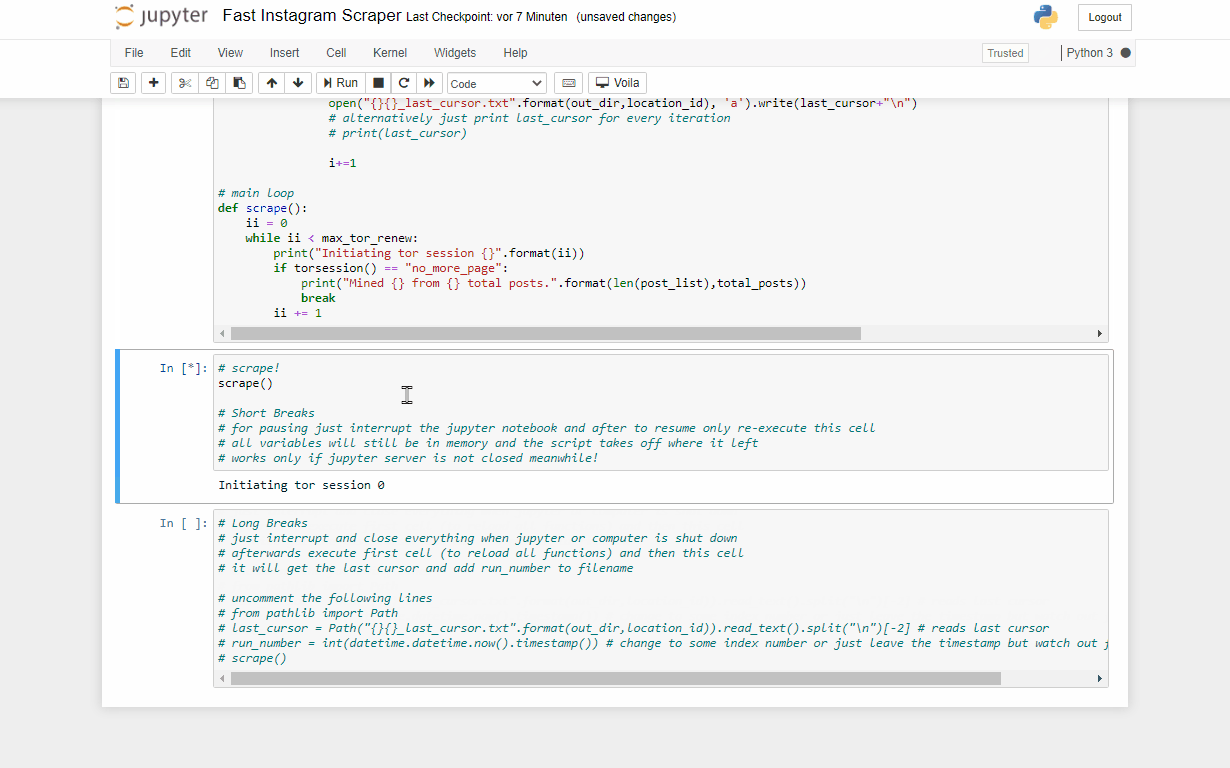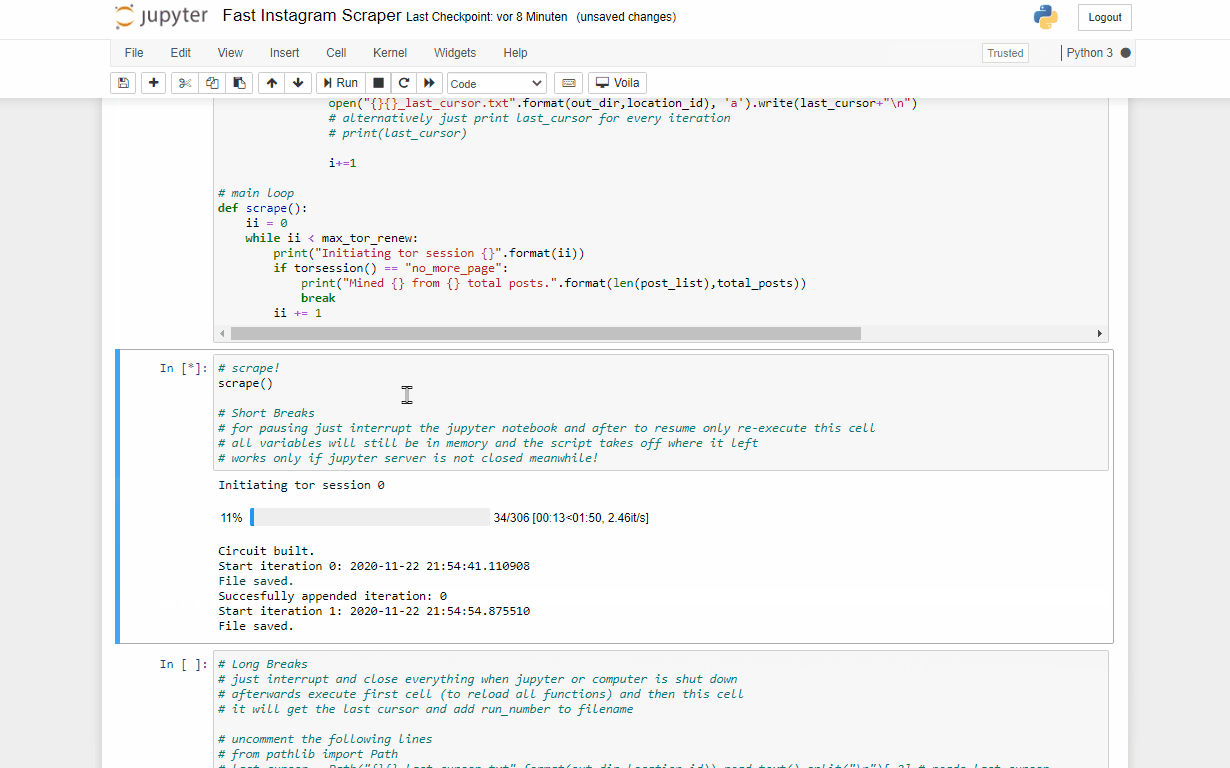
Use one tor end node to get as many requests as possible. Experience tells: a normal end node can do 15-40 requests (each one 50 posts) waiting around 10 seconds each time. Let’s do the math: if you got a good node, you’ll get 40x50 posts in 400 seconds which gives you a rate of 5 posts per second or even faster if you just want to <500 posts.